.png)
We are a global community of data science professionals, researchers and engineers that enjoy sharing ideas and learning from each other.
We organize monthly meetups with industry experts and leading companies in the Data and AI field. Visit our Meetup page to see any upcoming events.

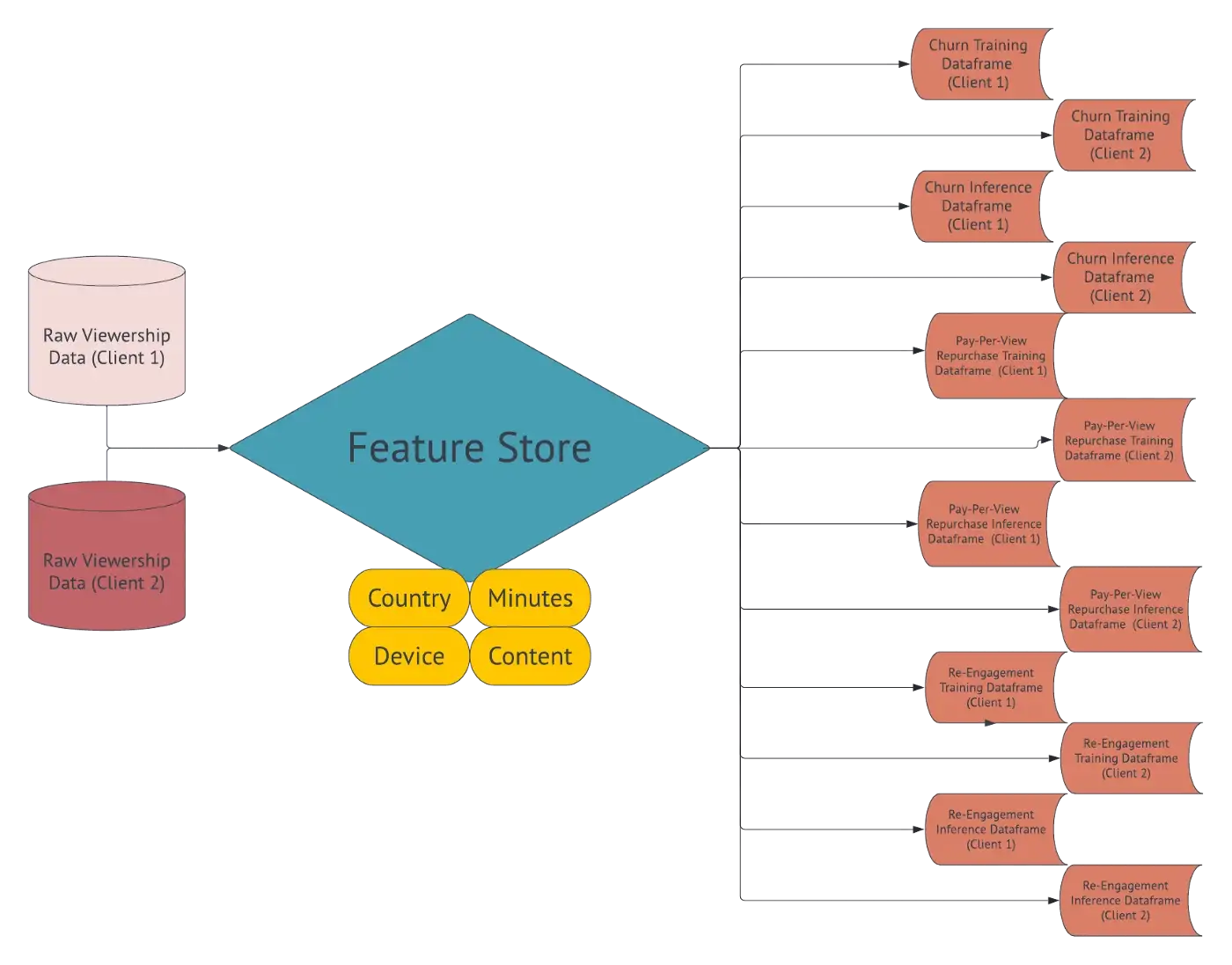
The first open-source Feature Store and the first with a DataFrame API. Most data sources (batch/streaming) supported. Ingest features using SQL, Spark, Python, Flink. The only feature store supporting stream processing for writes. Available as managed platform and on-premises.
A centralized repository for organizing, storing, and serving ML features on the GCP Vertex platform. Vertex AI Feature Store supports BigQuery, GCS as data sources. Separate ingestion jobs after feature engineering in BigQuery. Offline is BigQuery, Online BigTable.
Sagemaker Feature Store integrates with other AWS services like Redshift, S3 as data sources and Sagemaker serving. It has a feature registry UI in Sagemaker, and Python/SQL APIs. Online FS is Dynamo, offline parquet/S3.
A Feature Store built around Spark Dataframes. Supports Spark/SQL for feature engineering with a UI in Databricks. Online FS is AWS RDS/MYSQL/Aurora. Offline is Delta Lake.
One of the first feature stores from 2018, orginially called Zipline and part of the Bighead ML Platform. Feature engineering is using a DSL that includes point-in-time correct training set backfills, scheduled updates, feature visualizations and automatic data quality monitoring.
The mother of feature stores. Michelangelo is an end-to-end ML platfom and Palette is the features store. Features are defined in a DSL that translates into Spark and Flink jobs. Online FS is Redis/Cassandra. Offline is Hive.
Internal end-to-end ML Facebook platform that includes a feature store. It provides innovative functionality, like automatic generation of UI experiences from pipeline definitions and automatic parallelization of Python code.
Internal end-to-end ML platform at Apple. It automates the life cycle of model construction, deployment, and monitoring by providing a set of novel high-level, declarative abstractions. It has been used in production to support multiple applications in both near-real-time applications and back-of-house processing.
FeatureForm is a virtual feature store platfrom - you plug in your offline and online data stores. It supports Flink, Snowflake, Airflow Kafka, and other frameworks.
Twitter's first feature store was a set of shared feature libraries and metadata. Since then, they moved to building their own feature store, which they did by customizin feast for GCP.
Originally developed as an open-source feature store by Go-JEK, Feast has been taken on by Tecton to be a minimal, configurable feature store. You can connect in different online/offline data stores and it can run on any platform. Feature engineering is done outside of Feast.
Spotify built their own ML platform that leverages TensorFlow Extended (TFX) and Kubeflow. They focus on designing and analyzing their ML experiments instead of building and maintaining their own infrastructure, resulting in faster time from prototyping to production.
Intuit have built a feature store as part of their data science platform. It was developed for AWS and uses S3 and Dynamo as its offline/online feature serving layers.
A centralized and versioned feature storre built around their MLRun open-source MLOps orchestration framework for ML model management. Uses V3IO as it offline and online feature stores.
The platform allows to build real-time machine and deep learning features, upload ipython notebooks, monitor model drift, and set up CI/CD for machine learning systems.
A ML Platform with an effective online prediction ecosystem. It serves traffic on a large number of ML Models, including ensemble models, through their Sibyl Prediction Service.They extended Redis with sharding and compression to work as their online feature store.
ML Lake is a shared service that provides the right data, optimizes the right access patterns, and alleviates the machine learning application developer from having to manage data pipelines, storage, security and compliance. Built on an early version of Feast based around Spark.
Feathr automatically computes your feature values and joins them to your training data, using point-in-time-correct semantics to avoid data leakage, and supports materializing and deploying your features for use online in production.
Nexus supports batch, near real-time, and real-time feature computation and has global scale for serving online and offline features from Redis and Delta Lake-s3, respectively.
Robinhood built their own event-based real-time feature store based on Kafka and Flink.
FeatureByte is a solution that aims to simplify the process of preparing and managing data for AI models, making it easier for organizations to scale their AI efforts.
Fennel is a fully managed realtime feature platform from an-Facebook team. Powered by Rust, it is built ground up to be easy to use. It works natively with Python/Pandas, has beautiful APIs, installs in your cloud in minutes, and has best-in-class support for data/feature quality.
An open-source feature computing platform that offers unified SQL APIs and a shared execution plan generator for both offline and online engines, eliminating the need for cumbersome transformation and consistency verification.
Chalk is a platform for building real-time ML applications that includes a real-time feature store.
AGPL-V3
Hudi/Hive and pluggable
RonDB
No
AWS, GCP, On-Prem
Spark
DataFrame (Spark or Pandas), files (.csv, .tfrecord, etc)
No
Hive
Cassandra
None
Proprietary
Spark
DataFrame (Pandas)
No
GCS
Manhatten, Cockroach
Yes. Ingestion Jobs
Proprietary
BigQuery
DataFrame (Pandas)
No
Parquet
V3IO, proprietary DB
Unknown
AWS, Azure, GCP, on-prem
No details
DataFrame (Pandas)
No
BigQuery
BigTable
Yes. Ingestion Jobs
Proprietary
BigQuery
DataFrame (Pandas)
No
S3, Iceberg
DynamoDB
Yes. Ingestion Jobs
Proprietary
Iceberg
DataFrame (Pandas)
No
Pluggable
Pluggable
No
AWS, Azure, GCP, on-prem
No details
DataFrame (Pandas)
AGPL-V3
AWS, GCP, On-Prem
No
AWS, Azure, GCP, on-prem
No
AWS, Azure, GCP, on-prem
Developing a software can be extremely costly and time-consuming so reusability of different systems proves to be a reasonable solution, however the number of companies building their own feature store is on the rise.
Learn more about the industry's conundrum by watching the relevant panel discussion from the first Feature Store Summit.
Developing a software can be extremely costly and time-consuming so reusability of different systems proves to be a reasonable solution, however the number of companies building their own feature store is on the rise.
Learn more about the industry's conundrum by watching the relevant panel discussion from the latest Feature Store Summit.